'''
Tensorflow 설치
1. <https://www.microsoft.com/ko-kr> 연결
2. 다운로드 센터 클릭(<https://www.microsoft.com/ko-kr/download>)
3.개발자 도구 클릭
4. 05. Visual Studio 2015용 vISUAL c++ 재배포 가능 선택
5. 다운로드 클릭
6. vc_redist.x64.exe 선택 => 다음클릭 => 다운받기
7. 파일탐색기에서 vc_redict.x64.exe 실행
8. anaconda prompt를 관리자 모드로 실행
9. pip install tensorflow 치기
tensorflow 버전 확인 : 2.11.0
'''
📌
import tensorflow as tf
# .__version__ : 버전 확인 가능
print(tf.__version__) # 2.11.0
# 현재 컴퓨터가 GPU?
tf.config.list_physical_devices("GPU")
# []로 출력되면 GPU환경이 아님
# 텐서플로를 이용한 AND/OR 게이트 구현
data = np.array([[0,0], [0,1], [1,0], [1,1]])
**label = np.array([[0], [0], [0], [1]]) # 결과데이터 AND**
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import SGD
from tensorflow.keras.losses import mse
model = Sequential() # 딥러닝 모델
'''
Dense : 밀집층
1 : 출력값의 개수
input_shape : 입력값의 개수
activation : 활성화 함수 알고리즘
linear : 선형 함수
sigmoid : 0~1 사이의 값 변형
relu : 양수인 경우 선형함수, 음수인 경우 0
'''
model.add(Dense(1, input_shape=(2,), activation='linear'))
'''
compile : 모델 설정. 모형 설정
기증치 찾는 방법 설정
optimizer=SGD() : 경사하강법 알고리즘 설정.
loss=mse : 손실 힘수. mse : 평균제곱오차.
mse 값이 가장 적은 경우의 가중치와 평합 구함.
metrics=['acc'] : 평가 방법 지정. acc : 정확도
=> 손실함수의 값은 적은값. 정확도는 1에 가까운 가중치와 편향의 값을 찾도록 설정
'''
model.compile(optimizer=SGD(), loss=mse, metrics=['acc'])
# 학습하기
'''
data : 훈련데이터,
label : 정답
epochs=300 : 300번 반복 학습. 손실함수가 적고, 정확도가 높아지도록
verbose=0 : 학습과정 출력 생략
verbose=1 : 학습과정 상세 출력(기본값)
verbose=2 : 학습과정 간략 출력
'''
model.fit(data, label, epochs=300, verbose=0)
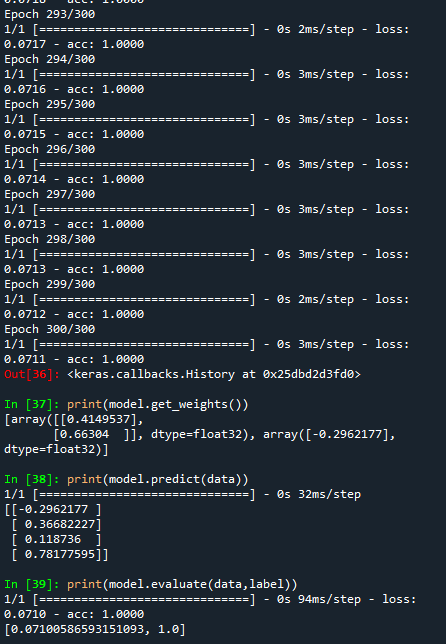
print(model.get_weights())
print(model.predict(data))
print(model.evaluate(data,label))
📌
import tensorflow as tf
# .__version__ : 버전 확인 가능
print(tf.__version__) # 2.11.0
# 현재 컴퓨터가 GPU?
tf.config.list_physical_devices("GPU")
# []로 출력되면 GPU환경이 아님
# 텐서플로를 이용한 AND/OR 게이트 구현
data = np.array([[0,0], [0,1], [1,0], [1,1]])
# label = np.array([[0], [0], [0], [1]]) # 결과데이터 AND
**label = np.array([[0], [1], [1], [1]]) # 결과데이터 OR**
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import SGD
from tensorflow.keras.losses import mse
model = Sequential() # 딥러닝 모델
'''
Dense : 밀집층
1 : 출력값의 개수
input_shape : 입력값의 개수
activation : 활성화 함수 알고리즘
linear : 선형 함수
sigmoid : 0~1 사이의 값 변형
relu : 양수인 경우 선형함수, 음수인 경우 0
'''
model.add(Dense(1, input_shape=(2,), activation='linear'))
'''
compile : 모델 설정. 모형 설정
기증치 찾는 방법 설정
optimizer=SGD() : 경사하강법 알고리즘 설정.
loss=mse : 손실 힘수. mse : 평균제곱오차.
mse 값이 가장 적은 경우의 가중치와 평합 구함.
metrics=['acc'] : 평가 방법 지정. acc : 정확도
=> 손실함수의 값은 적은값. 정확도는 1에 가까운 가중치와 편향의 값을 찾도록 설정
'''
model.compile(optimizer=SGD(), loss=mse, metrics=['acc'])
# 학습하기
'''
data : 훈련데이터,
label : 정답
epochs=300 : 300번 반복 학습. 손실함수가 적고, 정확도가 높아지도록
'''
model.fit(data, label, epochs=300)
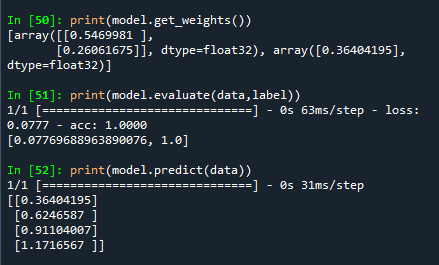
print(model.get_weights())
print(model.predict(data))
print(model.evaluate(data,label))
📌
import tensorflow as tf
# .__version__ : 버전 확인 가능
print(tf.__version__) # 2.11.0
# 현재 컴퓨터가 GPU?
tf.config.list_physical_devices("GPU")
# []로 출력되면 GPU환경이 아님
# 텐서플로를 이용한 AND/OR 게이트 구현
data = np.array([[0,0], [0,1], [1,0], [1,1]])
# label = np.array([[0], [0], [0], [1]]) # 결과데이터 AND
# label = np.array([[0], [1], [1], [1]]) # 결과데이터 OR
**label = np.array([[0], [1], [1], [0]]) # 결과데이터 XOR**
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import SGD
from tensorflow.keras.losses import mse
model = Sequential() # 딥러닝 모델
'''
Dense : 밀집층
1 : 출력값의 개수
input_shape : 입력값의 개수
activation : 활성화 함수 알고리즘
linear : 선형 함수
sigmoid : 0~1 사이의 값 변형
relu : 양수인 경우 선형함수, 음수인 경우 0
'''
model.add(Dense(1, input_shape=(2,), activation='linear'))
'''
compile : 모델 설정. 모형 설정
기증치 찾는 방법 설정
optimizer=SGD() : 경사하강법 알고리즘 설정.
loss=mse : 손실 힘수. mse : 평균제곱오차.
mse 값이 가장 적은 경우의 가중치와 평합 구함.
metrics=['acc'] : 평가 방법 지정. acc : 정확도
=> 손실함수의 값은 적은값. 정확도는 1에 가까운 가중치와 편향의 값을 찾도록 설정
'''
model.compile(optimizer=SGD(), loss=mse, metrics=['acc'])
# 학습하기
'''
data : 훈련데이터,
label : 정답
epochs=300 : 300번 반복 학습. 손실함수가 적고, 정확도가 높아지도록
verbose=0 : 학습과정 출력 생략
verbose=1 : 학습과정 상세 출력(기본값)
verbose=2 : 학습과정 간략 출력
'''
model.fit(data, label, epochs=300, verbose=0)
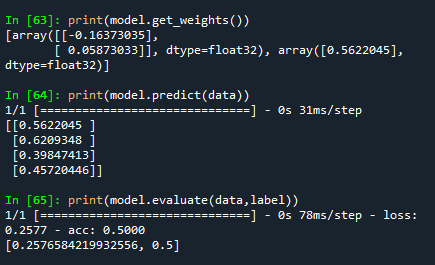
print(model.get_weights())
print(model.predict(data))
print(model.evaluate(data,label))
'수업(국비지원) > Python' 카테고리의 다른 글
| [Python] Fashion-MNIST 데이터를 이용하여 예측 평가하기 (0) | 2023.04.27 |
|---|---|
| [Python] MNIST 데이터를 이용하여 숫자를 학습하여 숫자 인식 (0) | 2023.04.27 |
| [Python] 딥러닝 - 가중치와 편향, 다중 퍼센트론 (0) | 2023.04.27 |
| [Python] 딥러닝 - 인공신경망(ANN) (0) | 2023.04.27 |
| [Python] 2022-12-28 복습 (0) | 2023.04.27 |



