카테고리 없음
[Python] 지도학습 예제 - 투수들의 연봉 예측하기
byeolsub
2023. 4. 26. 22:41
📌
#################################
# 투수들의 연봉 예측하기
#################################
import pandas as pd
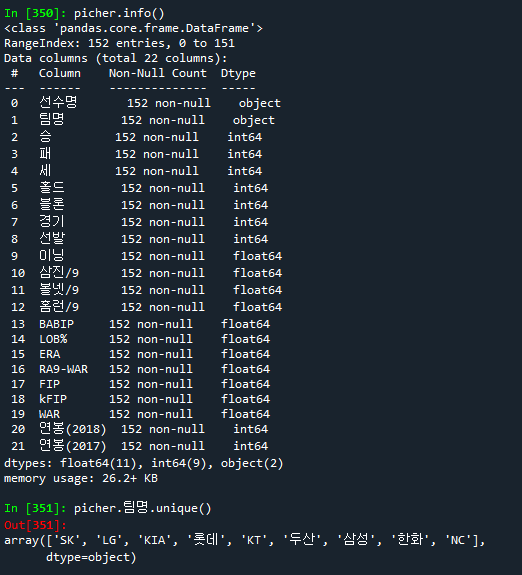
picher = pd.read_csv("data/picher_stats_2017.csv")
picher.info()
picher.팀명.unique()

# 팀명을 onehot_team 인코딩 하기. picher 데이터셋에 추가하기
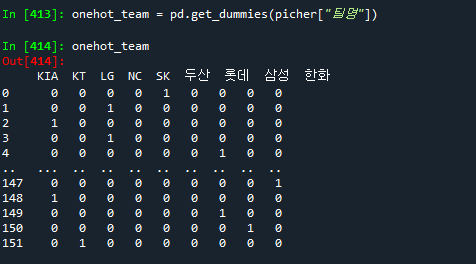
#1 팀명을 onehot_team 인코딩 하기
onehot_team = pd.get_dummies(picher["팀명"])
onehot_team
# picher 데이터셋에 추가하기
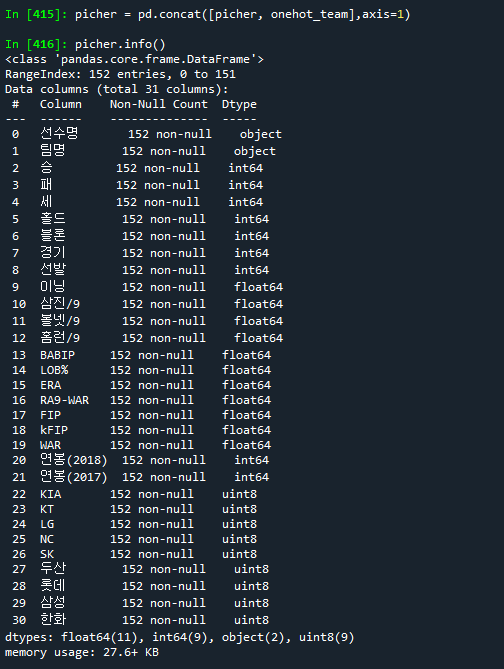
picher = pd.concat([picher, onehot_team],axis=1)
picher.info()
# 팀명 삭제
del picher["팀명"]

# 연봉(2018) => y컬럼으로 변경하기
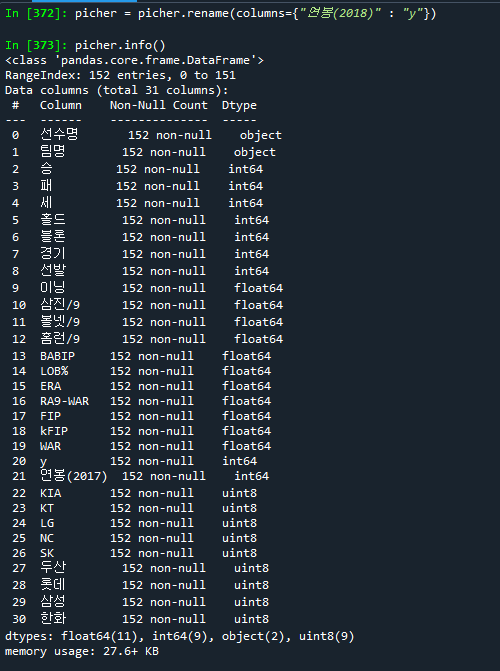
picher = picher.rename(columns={"연봉(2018)" : "y"})
picher.info()
# 독립변수, 종속변수 나누기
# 독립변수 : 선수명,y컬럼을 제외한 모든 컬럼
# 종속변수 : y컬럼
X = picher[picher.columns.difference(["선수명","y"])] # 설명변수
Y = picher["y"] # 목표변수

# 선택된 컬럼만 정규화 하기
# 표준값 : 값 - 평균 / 표준편차
def standard_scaling(df,scale_columns) :
for col in scale_columns :
s_mean = df[col].mean()
s_std = df[col].std()
df[col] = df[col].apply(lambda x : (x-s_mean)/s_std)
return df
# onehot_team.columns은 정규화에서 제외함
scale_columns = X.columns.difference(onehot_team.columns)
scale_columns
picher.head()
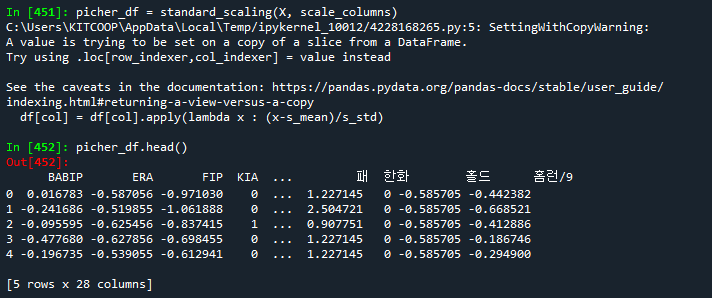
picher_df = standard_scaling(X, scale_columns)
picher_df.head()

# 훈련데이터와 테스트데이터로 분리하기
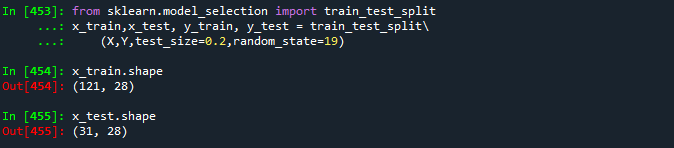
from sklearn.model_selection import train_test_split
x_train,x_test, y_train, y_test = train_test_split\\
(X,Y,test_size=0.2,random_state=19)
x_train.shape
x_test.shape
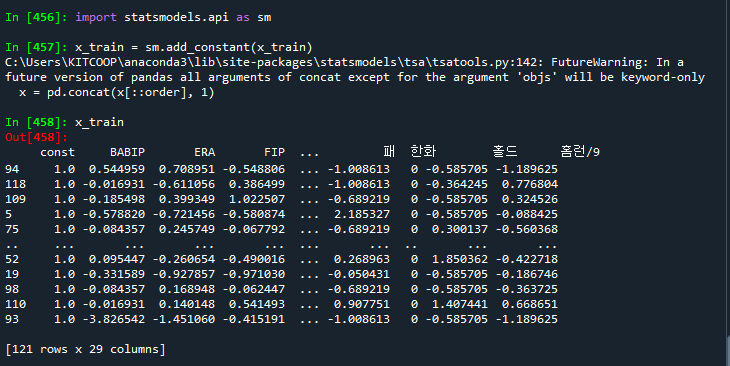
import statsmodels.api as sm
x_train = sm.add_constant(x_train)
x_train