#################################
# 머신러닝 : 기계학습. 예측에 사용. AI(인공지능)
# 변수(컬럼, 피처)들의 관계를 통해서 예측을 하는 과정
# 지도 학습 : 기계학습시 정답을 지정.
# 회귀분석 : 가격, 매출, 주가 예측등 연속성이 있는 데이터 예측에 사용
# 대략적인 추세를 분석한다?
# 분류 : 데이터 선택. 평가 ex) 사진을 보고 찾음
# yes or no
# 비지도 학습 : 기계학습시 정답이 없음.
# 군집 : 비슷한 데이터들끼리 그룹화함.
# 강화학습 : 행동을 할 때 마다 보상을 통해 학습하는 과정
# 머신러닝 프로세스()
# : 데이터 정리(전처리) -> 데이터 분리(훈련/검증/테스트) -> 알고리즘 준비
# -> 모형학습(훈련데이터를 이용) -> 예측(테스트데이터 이용) -> 모형평가 -> 모형활용
#################################
📌
'''
회귀 분석(regression)
단순 회귀분석 : 독립변수, 종속변수가 한개씩
독립변수(설명변수) : 예측에 사용되는 데이터 - 훈련데이터로 사용
종속변수(예측변수) : 예측해야 하는 데이터 - 정답데이터
'''
# 자동차 연비와 관련된 데이터
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
df = pd.read_csv("data/auto-mpg.csv")
df.info()
#1. horsepower 컬럼의 자료형을 flot 형으로 변경하기
# ?를 결측값으로 변경, 결측값행을 삭제.변경
#1-1 ?를 결측값으로 변경
df["horsepower"].replace("?",np.nan,inplace=True)
df["horsepower"].unique()
#1-2 결측값행을 삭제
df.dropna(subset=["horsepower"], axis=0, inplace=True)
df["horsepower"].unique()
# horsepower 컬럼의 자료형을 flot 형으로 변경하기
df["horsepower"] = df["horsepower"].astype(float)
df.info()

# 머신러닝에 필요한 속성(열, 컬럼, 변수,피처) 선택하기
ndf = df[['mpg','cylinders','horsepower','weight']]
ndf.corr()
sns.pairplot(ndf)

# 독립변수, 종속변수
X = ndf[["weight"]] # 독립변수. DataFrame 객체. 필수는 아님
Y = ndf["mpg"] # 종속변수. Series 객체. 값이 한개이기 때문에 Series로 많이 사용함.
len(X)
len(Y)

### 데이터 분리(훈련/테스트)
'''
train_test_split : 훈련/테스트 데이터 분리 함수.
임의의 순서로 데이터 분리
train_test_split(독립변수, 종속변수, test_size = 테스트데이터의 비율,
random_state = seed값)
test_size=0.3 : 70% 훈련데이터
30% 테스트데이터
기본값 : 0.25
random_state = seed값
seed설정 : 데이터의 복원을 위한 설정
'''
# sklearn : 머신러닝 모듈
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test =\\
train_test_split(X,Y,test_size=0.3,random_state=10)
len(X_train) # 392*0.7 = 274.4 => 274 : 훈련데이터 독립변수
len(X_test) # 392*0.3 = 117.6 => 118 : 테스트데이터 독립변수
len(Y_train) # 훈련데이터 종속변수
len(Y_test) # 테스트데이터 종속변수

📌
# 알고리즘 준비 : 선형회귀분석 : linearRegression
from sklearn.linear_model import LinearRegression
lr = LinearRegression() # 알고리즘 선택
# 모형학습
# lr : 학습이 완료된 선형 회귀분석 객체
lr.fit(X_train, Y_train)
# 예측
# X_test : 독립변수의 테스트 데이터
# y_hat : 예측 종속변수. 예측 연비값
# Y_hat : 실제 종속변수. 실제 연비값
y_hat = lr.predict(X_test)
# 모형 평가
y_hat[:10] # 예측데이터
Y_test[:10] # 실제데이터

r_square = lr.score(X_test, Y_test)
r_square # 결정계수. 값이 1에 가까울 수록 성능이 좋다.
# 결과 -> 0.6822458558299325
r_square = lr.score(X, Y)
r_square # 결과 -> 0.6919759765239987

# 전체 데이터 평가하기
y_hat = lr.predict(X) # 독립변수(weight)전체 데이터 예측
# => 예측된 종속변수(mpg)
# y_hat : 도형에서 예측된 데이터
# Y : 실제 데이터
# 실제 데이터와 예측데이터 시각화
# 히스토그램 그래프
# kdeplot : 값의 밀도
plt.figure(figsize=(10,5))
ax1 = sns.kdeplot(Y, label="Y") # 실제 데이터 밀도
ax2 = sns.kdeplot(y_hat, label="y_hat", ax=ax1) # 예측데이터 밀도
plt.legend()
plt.show()

📌
################
# 알고리즘 선택 : PloynomialFeatures.
# LinearRegression : 선형 회귀분석 : ax + b
# PolynomialFeatures : 다항 회귀분석 : ax**2 + bx + c
from sklearn.preprocessing import PolynomialFeatures
poly = PolynomialFeatures(2) # 2차항.
X_train.shape
# 데이터 전처리
# X_train 데이터를 다항식의 값으로 변환
X_train_poly = poly.fit_transform(X_train) # 다항식에 처리가능한 데이터
pr = LinearRegression()
pr.fit(X_train_poly, Y_train) # 모형 학습
# 평가데이터도 다항식 데이터로 변환
X_poly = poly.fit_transform(X)
y_hat = pr.predict(X_poly) # 예측
plt.figure(figsize=(10,5))
ax1 = sns.kdeplot(Y, label="Y")
ax2 = sns.kdeplot(y_hat, label="y_hat", ax=ax1)
plt.legend()
plt.show()
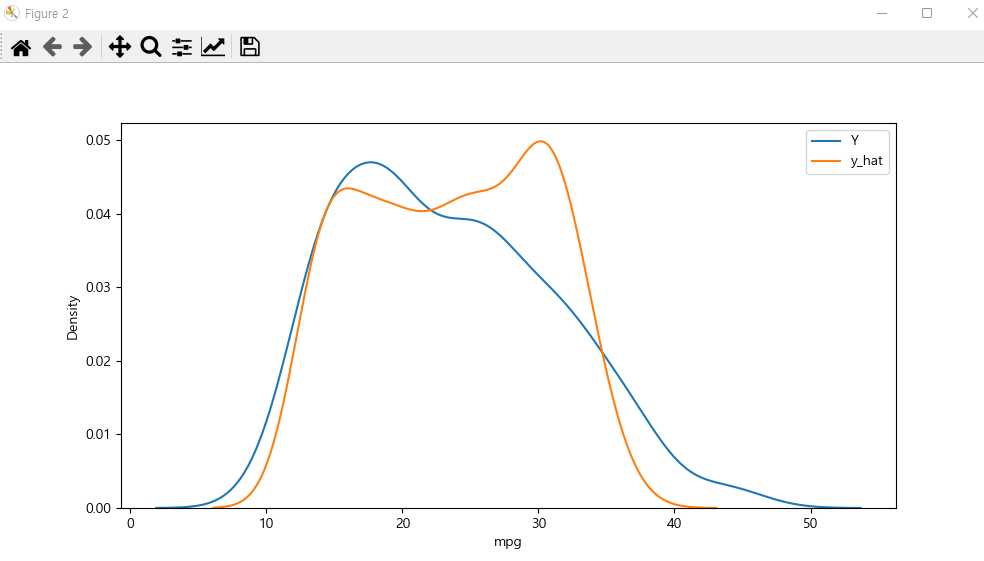
r_square = pr.score(X_poly, Y)
r_square # 결정계수. 값이 1에 가까울 수록 성능이 좋다.
# 결과 -> 0.7146983300645127
# 결정 계수 :1 - 잔차제곱의 합 / 총변환량
# 1- u/v
u = ((Y - y_hat)**2).sum()
v = ((Y - Y.mean())**2).sum()
1-(u/v) # 결과 -> 0.7146983300645127
'수업(국비지원) > Python' 카테고리의 다른 글
| [Python] 머신러닝 - 지도학습(분류) 1. KNN (0) | 2023.04.26 |
|---|---|
| [Python] 머신러닝 - 지도학습(회귀분석)3 (0) | 2023.04.26 |
| [Python] crime_in_Seoul.csv파일과 경찰관서 위치.csv파일 분석하기2 (0) | 2023.04.26 |
| [Python] crime_in_Seoul.csv파일과 경찰관서 위치.csv파일 분석하기 (0) | 2023.04.26 |
| [Python] CCTV_in_Seoul.csv파일과 population_in_Seoul.xls파일을 분석하기 (0) | 2023.04.26 |



