📌
### 중복데이터 처리
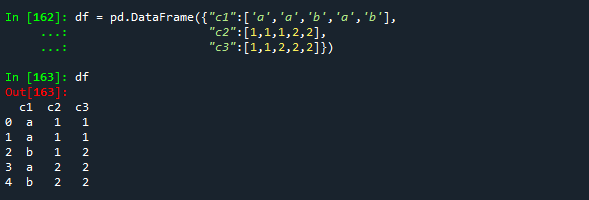
df = pd.DataFrame({"c1":['a','a','b','a','b'],
"c2":[1,1,1,2,2],
"c3":[1,1,2,2,2]})
df
# duplicated() : 중복데이터 찾기.
# 중복된 경우 중복된 두번째 데이터부터 True로 리턴
# 전체 행을 기준으로 중복 검색
df_dup = df.duplicated()
df_dup
df[df_dup] # 중복된 데이터만 조회

# c1컬럼을 기준으로 중복 검색
df["c1"].duplicated()

# c1컬럼을 기준으로 중복 검색
col_dup = df["c1"].duplicated()
df[col_dup]

# 중복된 데이터 제거하기
# drop_duplicates() : 중복된 행을 제거하기
df

# df 데이터의 중복없는 데이터 생성하기
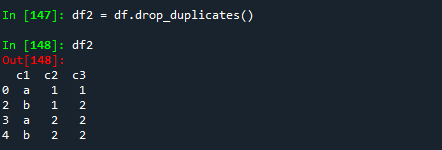
df2 = df.drop_duplicates()
df2 # 1번 하나 제거 됨.
# c1,c3 컬럼을 기준으로 중복 검색
col_dup = df[["c1","c3"]].duplicated()
df[col_dup] # 1,4번 인덱스

# c1,c3 컬럼을 기준으로 중복 제거하기
#subset 중복된 내용의 기준점
df3 = df.drop_duplicates(subset=["c1","c3"])
df3

📌
#auto_mpg.csv파일 읽기
mpg = pd.read_csv("data/auto-mpg.csv")
mpg.info()

# 컬럼 추가하기
#mile을 kilometer로 환산 원할 때
# kpl : kilometer per liter mpg * 0.425
#1. kilometer 컬럼 추가
mpg["kpl"] = mpg["mpg"]*0.425
mpg["kpl"]
mpg.info()

# kpl 컬럼의 데이터를 소숫점 1자리로만 변경하기
# 반올림하기
# round(1) : 소숫점 한자리로 반올림
mpg["kpl"] = mpg["kpl"].round(1)
mpg.kpl.head()
mpg.info()

# horsepower 컬럼의 값을 조회
mpg.horsepower.unique()

# 오류데이터 : ? => 처리.
# horsepower 컬럼을 숫자형으로 변환
# replace 함수 : 값을 변경
# ? => 결측값으로 변경
# np.nan : 결측값
mpg["horsepower"].replace("?",np.nan,inplace=True)
mpg.info()

# horsepower 값이 결측값인 행을 조회하기
mpg[mpg["horsepower"].isnull()]

# horsepower 값이 결측값인 행을 삭제하기
mpg.dropna(subset=["horsepower"],axis=0,inplace=True)
mpg.info()

# horsepower 자료형을 실수형으로 변환하기
# astype(자료형) : 시리즈객체에 있는 모든 요소들을 자료형을 변환.
mpg["horsepower"] = mpg["horsepower"].astype("float")
mpg.info()

'수업(국비지원) > Python' 카테고리의 다른 글
| [Python] 범주형 데이터2 - 주식데이터 읽기 (0) | 2023.04.25 |
|---|---|
| [Python] 범주형 데이터1 (0) | 2023.04.25 |
| [Python] 데이터 전처리 (0) | 2023.04.25 |
| [Python] 빅데이터 분석 예제 (0) | 2023.04.25 |
| [Python] numpy 연산 (0) | 2023.04.25 |



